

引用本文: 田翩, 何培宇, 蔡杰, 趙啟軍, 李莉, 錢永軍, 潘帆. 基于多特征融合網絡的心音分割方法研究. 中國胸心血管外科臨床雜志, 2024, 31(5): 672-681. doi: 10.7507/1007-4848.202310060 復制
版權信息: ?四川大學華西醫院華西期刊社《中國胸心血管外科臨床雜志》版權所有,未經授權不得轉載、改編
心血管疾病已成為全球最大的死亡原因,僅中國每年約有254萬人因心血管疾病死亡[1],盡早診斷對心血管疾病的治療極為關鍵。臨床醫學中常用的心血管疾病診斷方法包括電子計算機斷層掃描(computed tomography,CT)、心血管超聲、心臟聽診等,其中心臟聽診對設備要求較低,能避免診斷環節中使用昂貴的醫療設備給患者帶來的經濟負擔,常應用于心血管疾病的早期檢查。
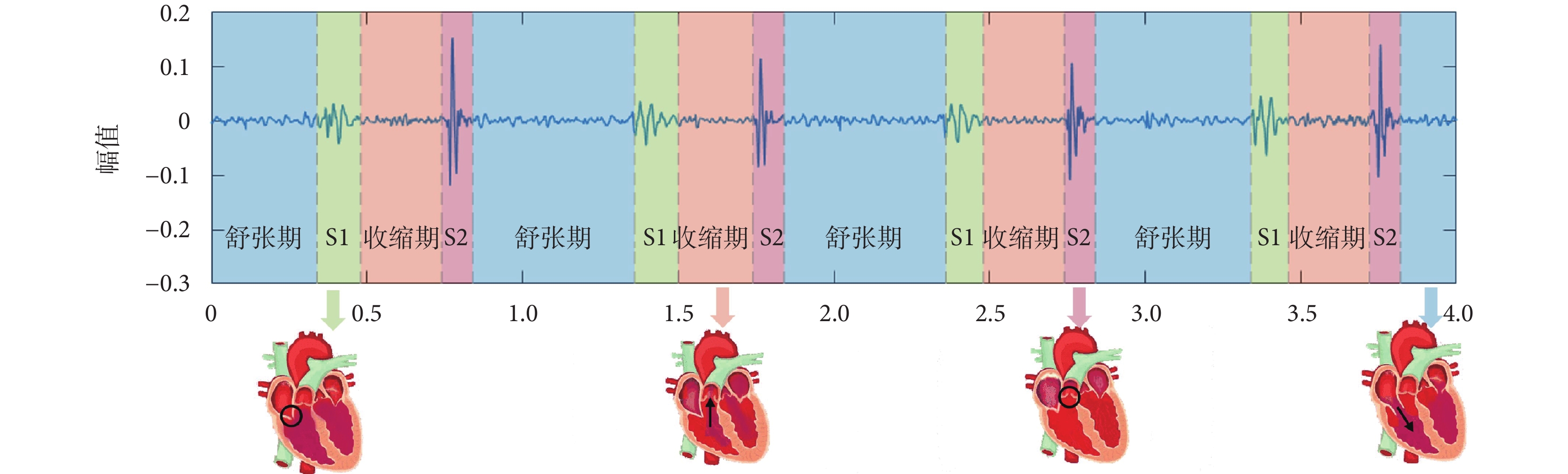
在醫生進行臨床心臟聽診時關注的信號是心音,心音由心臟的機械震動傳導至體表產生,又被稱為心音圖(phonocardiogram,PCG)。一個基本心音會依次經歷4種狀態:第一心音(first heart sound,S1)、收縮期(systole,sys)、第二心音(second heart sound,S2)、舒張期(diastole,dis);見圖1。當心室開始收縮時,房室瓣關閉而產生S1,在收縮期,血液從心室經動脈瓣流向動脈,當心室開始舒張時,動脈瓣關閉而產生S2;在舒張期,血液從心房經房室瓣流向心室。心音分割的任務就是從心音圖中準確定位每一種狀態。
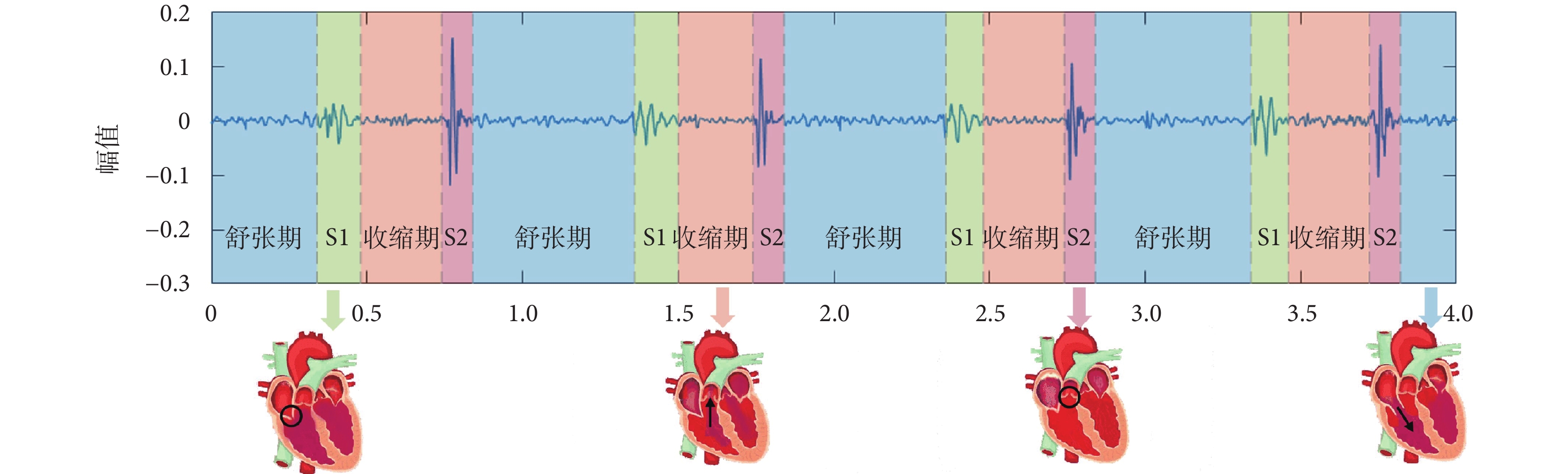 圖1
心音示意圖
圖1
心音示意圖
臨床心音聽診的診斷結果需結合心音分割的結果分析,因此心音分割是心臟聽診中的一項重要任務。例如,在觀察患者是否出現心音分裂或強度異常時,需準確定位S1與S2,然后具體分析;在判斷患者是否出現異常心臟結構時,需準確定位舒張期與收縮期,當觀測到患者舒張期出現連續雜音,一般都是病理性雜音;而當患者出現收縮期雜音,則可能是病理性,也可能是正常心臟結構的血流量增加[2]。
近年來,在心音分割領域出現了許多有效的分割方法,現有的心音分割方法包括基于信號特征的心音分割、基于傳統模型的心音分割與基于深度學習網絡的心音分割[3]。
基于信號特征的心音分割[4–8]主要利用信號在時域、頻域、時頻域的信息。如曾勁云等[4]與Belmecheri等[5]利用心音的頻譜與包絡信息,Babu等[7]通過變分模態分解提取信號中的特征,Varghees等[8]通過經驗小波變換提取信號中的特征。這些方法在信號特征的基礎上,結合門限法實現心音分割,但判別門限對噪聲較為敏感,當背景噪聲較強時,會影響特征的包絡,而實踐中的心音往往伴隨著環境噪聲,背景噪聲是此方法在實踐中推廣的一個重大難題。
基于傳統模型的心音分割則是在信號特征的基礎上結合了其他傳統模型。例如隱馬爾可夫模型(hidden Markov model,HMM)[9-10]與隱半馬爾可夫模型(hidden semi-Markov model,HSMM)[11–15],這兩種模型從訓練集的觀察特征與狀態序列上學習狀態轉移概率、觀測概率、初始狀態概率等信息[13],實現在測試集上根據觀察特征預測對應的狀態序列,從而完成心音分割。HSMM相較HMM模型,還利用了狀態的持續時間概率分布作為模型的參數,能有效提升心音分割性能[11],但非規律性的心音與訓練集中樣本的狀態持續時間差異較大,模型的持續時間概率分布不再匹配,對這部分樣本,S1與S2分割出錯的可能性提升[16]。除此之外,Xu等[17]還利用聚類模型K-Means對基于信號特征的分割結果進行聚類,排除異常的識別結果,但這種方法對于雜音等級較高的異常心音,分割性能較差。
隨著深度學習網絡強大學習能力的展現,大量深度學習網絡也運用到了心音分割中,并取得了比上面兩種方法更好的性能表現。Renna等[18]與Chen等[19]均通過卷積神經網絡(convolutional neural networks,CNN)實現心音分割。但從理論上來講,CNN存在長時依賴問題,具體表現在容易丟失之前時刻提取的心音信息,相比之下,循環神經網絡(recurrent neural network,RNN)能取得更好的性能[20–22]。Messner等[16]對多種RNN的心音分割性能進行了比較,如長短時記憶網絡(long short term memory,LSTM)、門控循環單元(gated recurrent unit,GRU)及它們的雙向結構,試驗證明BiGRU能取得最佳的性能,且比HSMM模型表現更佳。此外,部分學者對LSTM模型進行了改進,如Chen等[3]提出Duration-LSTM,向網絡中加入患者心音的時長參數;Wang等[23]提出基于LSTM的TFAN網絡;Guo等[24]使用卷積與注意力機制,提出C-LSTM-A網絡,都相較LSTM取得了一定的心音分割性能提升。
基于深度學習網絡的心音分割已取得較好的結果,之前研究往往聚焦于分割網絡結構,但實際上特征工程是網絡模型中的重要一環,對網絡的性能有重要影響。前面的網絡模型輸入特征較為單一,或者特征間的融合處理較為簡單,未充分利用不同特征間的區別與聯系,本研究在BiGRU網絡的基礎上,重點關注網絡輸入特征的處理,實現了一個基于多特征融合網絡的心音分割方法。
1 資料與方法
1.1 數據采集
試驗中使用的數據集來自2016 CinC/PhysioNet心音挑戰賽[25]。該比賽的訓練集為開源數據集,常用于心音分割方法的性能評估,由6個獨立的機構提供,記為PN-training-a至PN-training-f,包括從764例患者中采集的3 153段正常或異常心音記錄,長度5~120 s,采樣率為2 000 Hz。數據集包含正常心音與異常心音,其中異常心音記錄樣本主要與二尖瓣脫垂(mitral valve prolapse,MVP)、良性雜音(benign)、主動脈疾病(aortic disease,AD)、其他病理狀況(miscellaneous pathological conditions,MPC)、冠狀動脈疾病(coronary artery disease,CAD)、二尖瓣反流(mitral regurgitation,MR)、主動脈狹窄(aortic stenosis,AS)和病理學(pathologic)相關。
此外,這個數據集中還標注了每段心音4種狀態的開始與結束時刻,以及信號質量差的心音片段。在本試驗中,剔除了含質量差片段的313段心音,并按將同一例患者的數據僅包含在一個數據集中的規則,將剩余數據劃分為訓練集與測試集,最終得到的數據集見表1。
1.2 整體框架
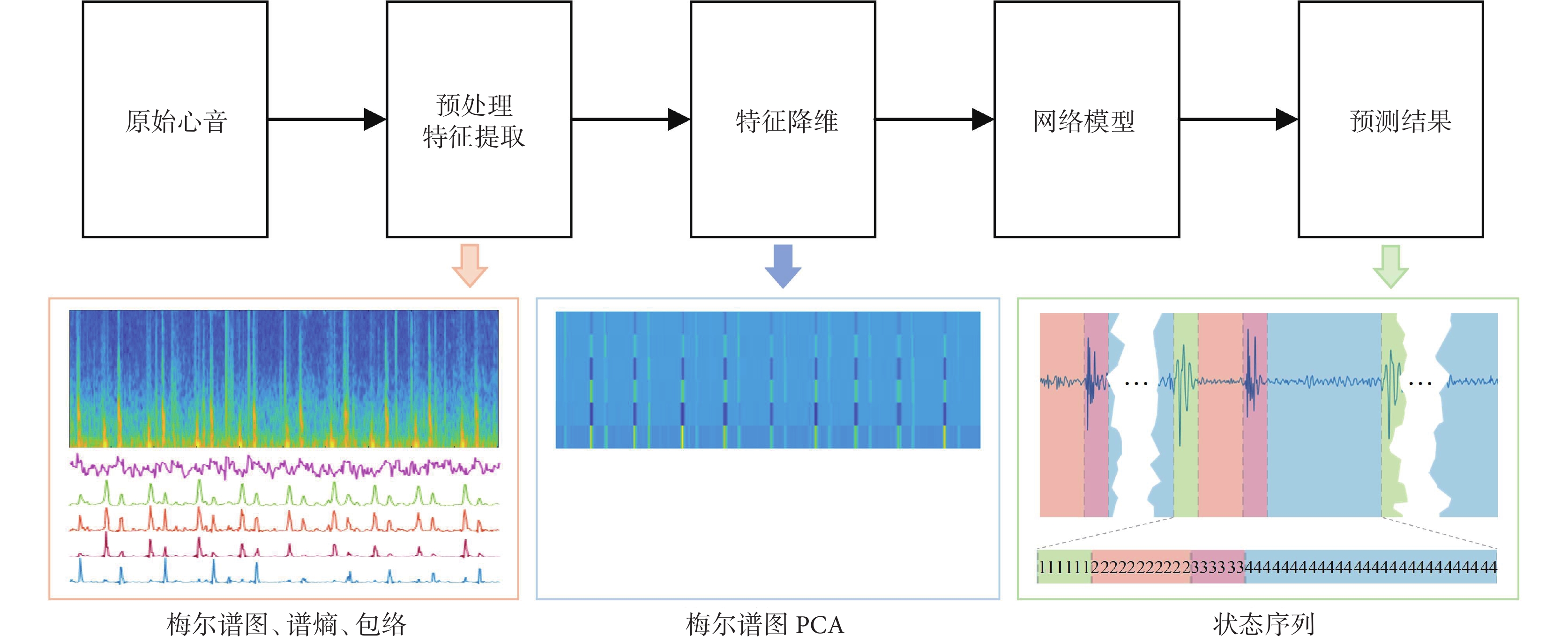
本文提出的方法包括數據集劃分、預處理、特征提取、特征降維、特征選擇與網絡訓練等步驟,主要處理過程的框架見圖2。
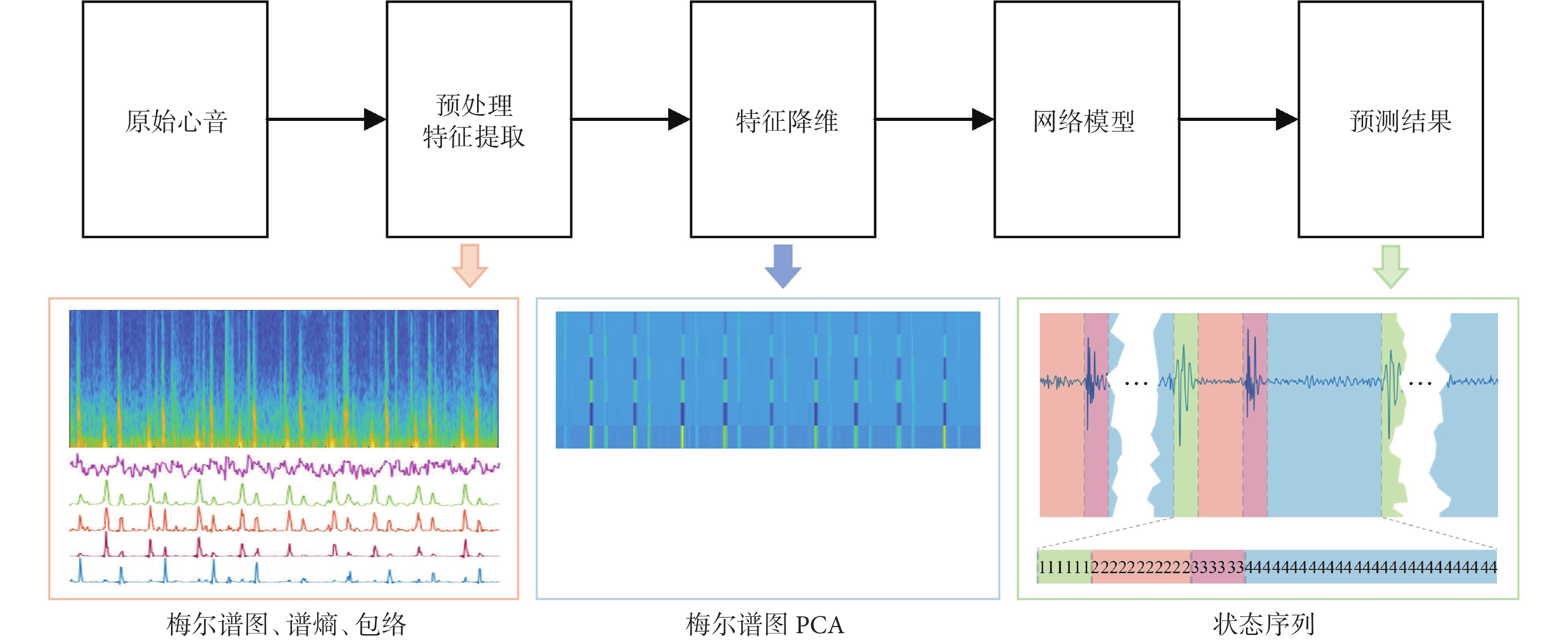 圖2
心音分割方法整體框架
圖2
心音分割方法整體框架
PCA:主成分分析
1.3 特征提取
心音的主要能量分布在150 Hz以下,對數據集的音頻,進行了如下處理:首先通過一個截止頻率為25 Hz與400 Hz、階數為4的巴特沃斯帶通濾波器濾除心音中的高頻噪聲與低頻直流偏置,并將音頻不重疊地切分為10 s的音頻,<2 s的音頻可能不含完整的心音,這部分音頻在試驗中舍棄,其他<10 s的音頻末端補0。切分后,訓練集與測試集分別包含5 396、1 985段音頻。
對心音進行特征提取時,分別從時頻域與時域兩種特征空間提取特征,兩個特征空間中主要包含如下特征。
(1)時頻域特征:① 梅爾譜圖(Mel spectrum,Mels):頻譜圖能表現音頻的短時頻譜隨時間的變化,Mels在頻譜圖的基礎上,進一步使用梅爾濾波器組來設計頻帶,更符合人的聽覺機理,試驗中使用了包含64個濾波器的梅爾濾波器組計算Mels,濾波器頻率范圍為25~400 Hz;② 梅爾倒譜系數(mel-frequency cepstral coefficients,MFCCs):MFCCs常用于語音識別中,試驗中使用含20個濾波器的梅爾濾波器組提取了20個MFCCs,濾波器的頻率范圍為25~400 Hz,并以9為窗長提取了MFCCs的20個一階導、20個二階導。
(2)時域特征:① 包絡特征(envelopes):包絡特征是心音分割中用到最多的特征,包含同態包絡、希爾伯特包絡、小波包絡與功率譜密度[11];② 譜熵(spectral entropy,SE):譜熵常用于音頻的端點檢測中,計算信號歸一化譜概率密度函數的熵,表現信號在頻域分布的無序性隨時間的變化[26]。
其中,Mels、MFCCs與譜熵的計算均需進行分幀操作,試驗中使用80 ms窗長、20 ms幀移的漢明窗完成;計算包絡特征時為保證與其他特征具有同樣的特征采樣率,進行了采樣率為50 Hz的降采樣;此外,對于每段音頻的不同特征,在特征提取后還進行了歸一化處理。
為獲取每段心音真實的分割結果,試驗根據給出的狀態起止時刻標注,每20 ms進行一次狀態標記,最終得到采樣率為50 Hz的真實狀態序列。
1.4 特征降維
完成特征提取后,所得到的特征存在維度過高與維度間相關性較強的問題。例如,Mels一般維度較高,相鄰頻段的帶寬部分重疊,頻段內計算的能量相關性較強[27]。試驗通過主成分分析(principal components analysis,PCA)來實現特征降維[28],同時減少輸入特征間的相關性。
PCA主要運用了相關矩陣與特征值分解,將初始特征向量轉換為一組不相關的特征向量。對于含k個樣本的n維特征向量 ,通過式(1)對每個維度中心化,得到中心化特征向量
,通過式(1)對每個維度中心化,得到中心化特征向量 ;按式(2)求中心化特征向量的協方差矩陣
;按式(2)求中心化特征向量的協方差矩陣 ,式中
,式中 {·}表示數學期望;對
{·}表示數學期望;對 進行特征值分解得到一組從大到小排序的特征值
進行特征值分解得到一組從大到小排序的特征值 與對應的特征向量
與對應的特征向量 ;若希望保留
;若希望保留 個主成分,則按式(3)得到
個主成分,則按式(3)得到 維的降維特征,其中第
維的降維特征,其中第 個主成分的可解釋方差為
個主成分的可解釋方差為 ,貢獻度為
,貢獻度為 。
。
 '/> '/> |
 '/> '/> |
 |
1.5 網絡模型
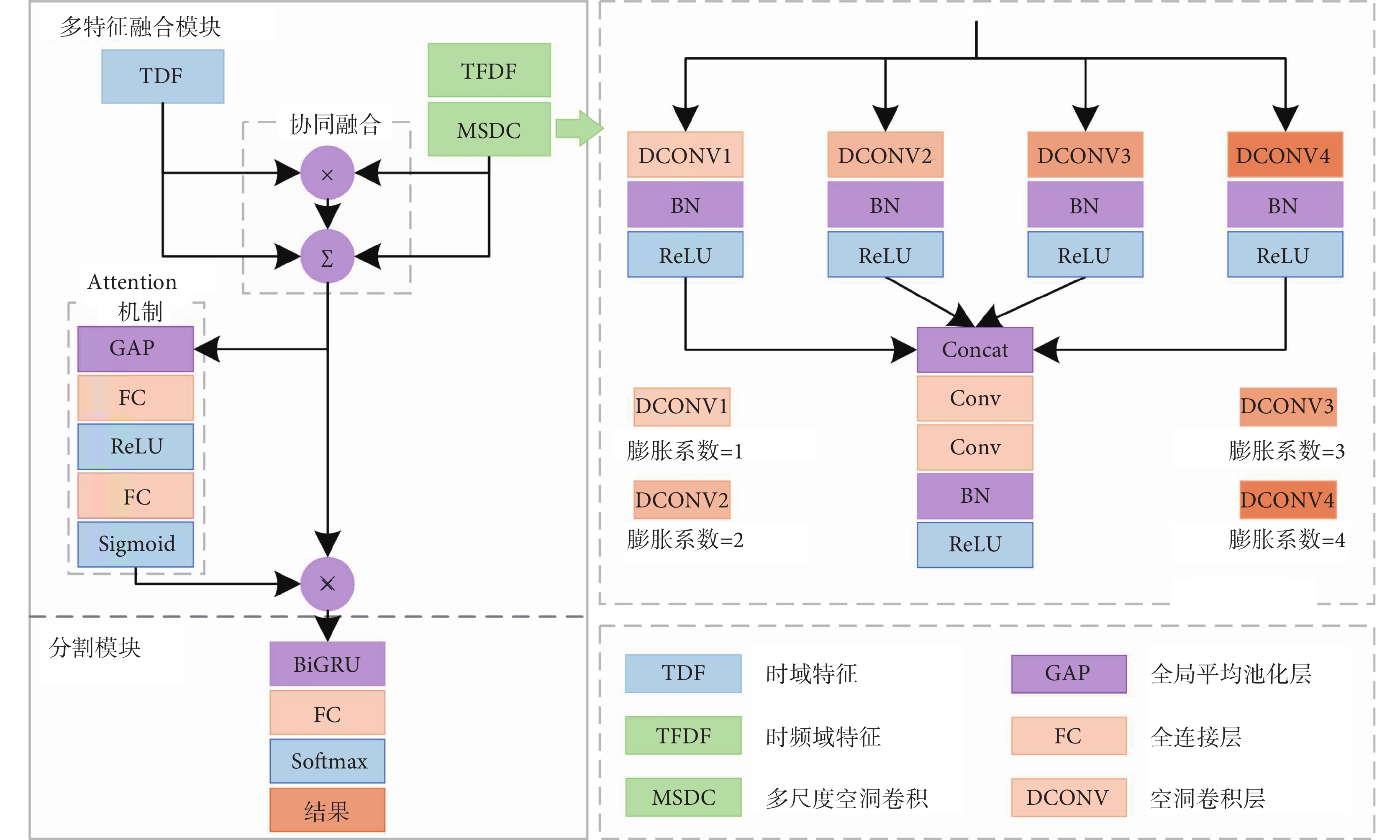
本文提出的網絡結構見圖3,經過特征選擇后,從兩個特征空間中選擇的心音分割性能最佳的特征作為網絡的輸入。網絡先完成多特征融合任務,得到融合特征,再將融合特征送入分割模塊,完成心音分割任務,得到預測的狀態序列。該網絡在多特征融合模塊主要使用了多尺度空洞卷積、協同融合與通道注意力機制(attention),在分割模塊使用了BiGRU網絡。
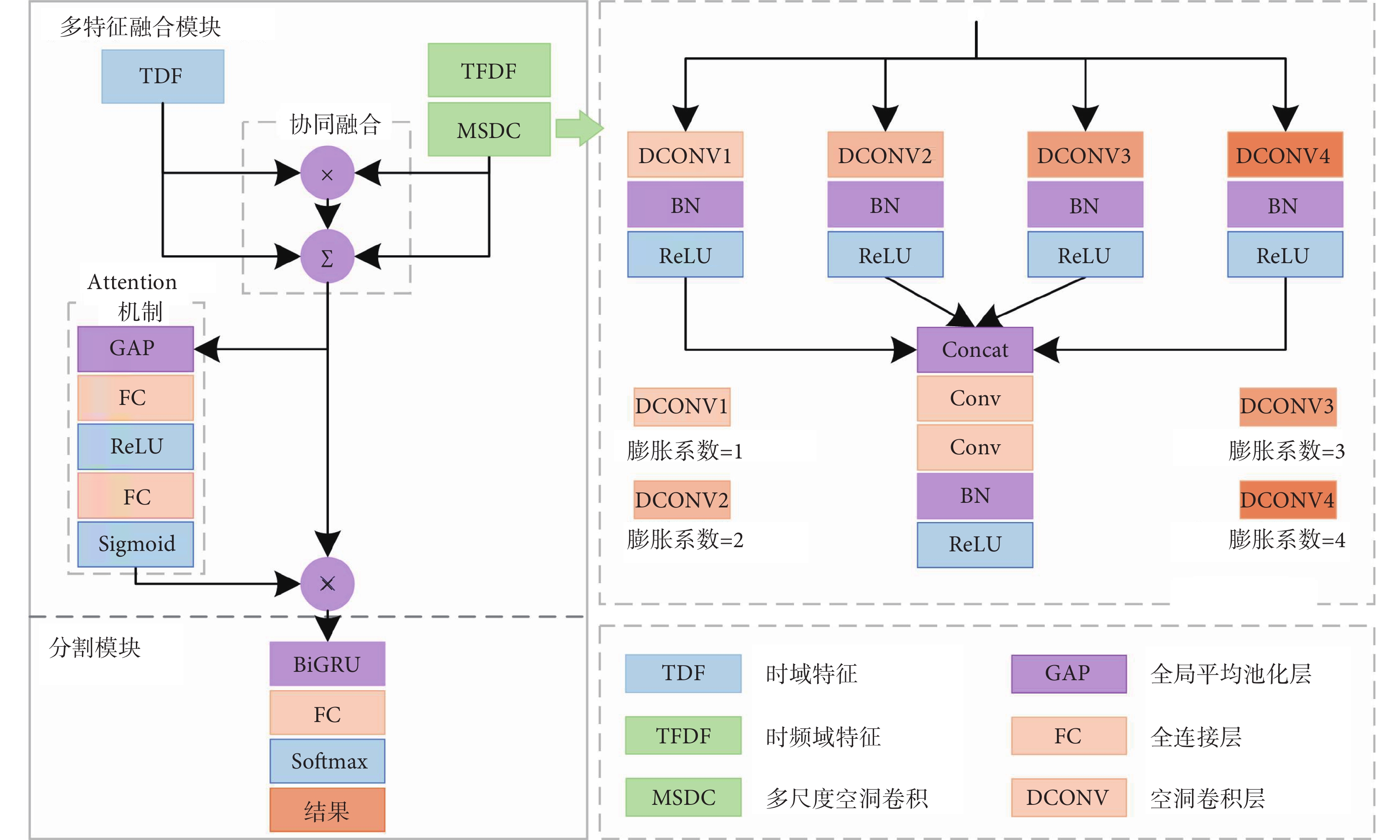 圖3
網絡結構圖
圖3
網絡結構圖
1.5.1 多尺度空洞卷積
在特征選擇后,得到時域特征 與時頻域特征
與時頻域特征 ,試驗中
,試驗中 與
與 一般不相等,如本試驗中
一般不相等,如本試驗中 =5,
=5, =6。為確保協同融合前兩個特征空間中特征維度一致,網絡中使用了多尺度空洞卷積改變時頻域特征維度[29]。
=6。為確保協同融合前兩個特征空間中特征維度一致,網絡中使用了多尺度空洞卷積改變時頻域特征維度[29]。
該網絡的多尺度空洞卷積使用了膨脹系數分別為1、2、3、4的4種卷積核對 進行空洞卷積,得到4種尺度的特征圖
進行空洞卷積,得到4種尺度的特征圖 ,每個卷積核的大小為10,對應的感受野大小分別為200 ms、380 ms、560 ms、740 ms。將4種特征圖拼接得到拼接特征
,每個卷積核的大小為10,對應的感受野大小分別為200 ms、380 ms、560 ms、740 ms。將4種特征圖拼接得到拼接特征 ,通過卷積與激活等操作逐步降維,得到與時域特征維度一致的時頻域特征
,通過卷積與激活等操作逐步降維,得到與時域特征維度一致的時頻域特征 。使用包含
。使用包含 個神經元的卷積層對
個神經元的卷積層對 進行處理時,兩個特征空間中的特征維度也能實現統一,但相比而言,多尺度空洞卷積聚合了多尺度的心音特征,能提取更豐富的心音上下文信息。
進行處理時,兩個特征空間中的特征維度也能實現統一,但相比而言,多尺度空洞卷積聚合了多尺度的心音特征,能提取更豐富的心音上下文信息。
1.5.2 協同融合
將時域特征 與多尺度空洞卷積處理后的時頻域特征
與多尺度空洞卷積處理后的時頻域特征 送入協同融合模塊(圖3),其過程描述為:
送入協同融合模塊(圖3),其過程描述為:
 |
式中“ ”表示點加,“
”表示點加,“ ”表示點乘,按式(4)進行計算,得到協同融合的輸出特征
”表示點乘,按式(4)進行計算,得到協同融合的輸出特征 ,與輸入特征具有相同的維度。Fu等[30]的研究證明,雖然不同特征通過拼接的方式也能實現融合,但這樣的融合方式往往會使模型的訓練結果陷入局部最優,如在本試驗中偏向從時域特征學習心音分割。
,與輸入特征具有相同的維度。Fu等[30]的研究證明,雖然不同特征通過拼接的方式也能實現融合,但這樣的融合方式往往會使模型的訓練結果陷入局部最優,如在本試驗中偏向從時域特征學習心音分割。
1.5.3 通道注意力機制
為根據不同樣本動態調整不同特征通道的重要性權重,網絡在協同融合的輸出特征上使用了通道注意力機制[31]。通道注意力機制可描述為:
 |
 |
其中 (·)表示全局平均池化,
(·)表示全局平均池化, (·)表示第
(·)表示第 個全連接層。對協同融合后的得到的特征
個全連接層。對協同融合后的得到的特征 ,根據式(5)計算出的每個通道的注意力權重
,根據式(5)計算出的每個通道的注意力權重 ,通過式(6)完成加權后,得到融合特征
,通過式(6)完成加權后,得到融合特征 。
。
1.5.4 雙向門控循環單元
門控循環單元由Chung 等[32]提出,通過重置門使網絡遺忘過去時刻的狀態,通過更新門決定網絡的更新狀態,GRU網絡由多個門控循環單元構成。
假設網絡的前一時的刻激活狀態為 ,當前的輸入為
,當前的輸入為 ,那么網絡重置門、候選狀態與更新門分別表示為式(7)~(9)。其中重置門
,那么網絡重置門、候選狀態與更新門分別表示為式(7)~(9)。其中重置門 主要用在候選狀態
主要用在候選狀態 的計算中,決定對
的計算中,決定對 的遺忘程度,當
的遺忘程度,當 接近0時,可認為當前單元的候選狀態僅由當前輸入決定;更新門
接近0時,可認為當前單元的候選狀態僅由當前輸入決定;更新門 主要用在當前時刻的激活狀態
主要用在當前時刻的激活狀態 的計算中,用來決定對
的計算中,用來決定對 與
與 的激活程度。最終由式(10)得到
的激活程度。最終由式(10)得到 ,可理解為候選狀態
,可理解為候選狀態 與
與 的線性組合。
的線性組合。
 |
 |
 |
 |
上面的GRU單元的當前狀態與前一時刻的激活狀態有關,而在實際的心音分割過程中,某一時刻的狀態判斷需綜合參考前一時刻激活狀態與后一時刻激活狀態,故試驗中使用的是BiGRU。在BiGRU中,兩個單獨的GRU隱藏層分別處理兩個方向上的數據,前向激活狀態 描述為式(11),反向激活狀態
描述為式(11),反向激活狀態 描述為式(12),則BiGRU的激活狀態為
描述為式(12),則BiGRU的激活狀態為 與
與 的組合
的組合 。
。
 |
 |
1.6 評估指標
對方法分割結果進行評估時,試驗比較了真實狀態序列與預測結果中的每種狀態,當某狀態的起止時間與標簽均一致時,則認為該狀態判斷正確,同時,本文允許每種狀態的起止點存在40 ms的誤差。對于每種狀態,記錄了下列事件的發生次數:真陽性(true positive,TP):真實狀態序列與預測結果中,狀態標簽一致,起止時間在誤差允許范圍內;真實發生(number of ground truth,GTN):在真實狀態序列中,該狀態出現;預測發生(number of prediction,PN):在預測結果中,該狀態出現。
由上面的數據,根據公式(13)~(18)計算精確率(precision,Pre)、靈敏度(sensitivity,Se)、F1值與錯誤率(error rate,Err),作為心音分割性能評估指標。
 |
 |
 |
 |
 |
 |
1.7 實現細節
在通過PCA完成特征降維時,相比時域特征,時頻域特征維度較高,主要在時頻域上進行特征降維。在對PCA保留維數的選擇上,分別選擇保留99%可解釋方差與保留95%可解釋方差的對應維數;在計算式(2)中協方差矩陣時,使用訓練集中樣本進行估計,并將得到的特征向量通過式(3)分別應用在訓練集與測試集上,完成特征降維。
本文網絡基于pytorch1.11框架實現,輸出狀態序列包含5種狀態,分別是補0、S1、收縮期、S2與舒張期;網絡中所有的卷積均采用“same”卷積模式,保證卷積前后特征的幀數不變;網絡的BiGRU參數參考Messner等[16]得到的最優參數:“dropout”設置為0.1,雙層,每個隱藏狀態包含100個特征;在訓練網絡參數的過程中使用了ADAM優化器與交叉熵損失函數。此外,為均衡模型在正常與異常心音上的分割性能,在訓練模型時,對正常心音樣本與異常心音樣本采用了不同的采樣權重,使得兩者等比例參與訓練。
在模型比較時,為了綜合考慮每種心音狀態,每次試驗對S1、收縮期、S2、舒張期的評估結果取均值。在網絡訓練的過程中,試驗結果具有隨機性,為了提高結果評估結果的可靠性,在每種方法上進行了10次訓練,每次訓練均完成200輪迭代,最終對10次訓練的結果取均值與方差。在對其他模型進行復現時,采用了與本文一致的數據集劃分。但由于Springer等[11]與Wang等[23]使用的模型在預測時候使用了維特比譯碼,且在分割狀態中僅存在心音的4種狀態,在復現時使用了參考論文中的切分方法,未對心音進行補0。其他對比模型采用了與本文相同的心音切分方法。
2 結果
2.1 特征降維結果
在訓練集上,根據式(2)分別估算心音Mels與MFCCs的協方差矩陣,對兩者實現特征降維。本文提取的Mels特征維度為64維,MFCCs特征維度為60維,在保留99%可解釋方差后,Mels的特征降至11維,MFCCs的特征維度降至7維;在保留95%可解釋方差后,Mels的特征維度降至6維,MFCCs的特征維度降至4維。降維后的特征不同維度間線性無關,且保留了原始特征的主要信息。
2.2 特征選擇結果
在BiGRU網絡上分別利用兩種特征空間的特征進行心音分割任務,從兩種特征維度中分別選取表現最佳的特征,結果見表2。
在時域上,由于譜熵為一維特征,維度較低,未進行基于譜熵的心音分割試驗。試驗結果表明,相比僅使用4種包絡作為輸入特征,4種包絡與譜熵的拼接在準確率、靈敏度、F1值與錯誤率的表現上都有一定提升。在時頻域上,MFCCs與Mels均包含心音豐富的時頻域信息,經PCA處理后保留了時頻域信息中的大部分可解釋方差,試驗中分別使用MFCCs、Mels與它們PCA處理后的特征作為網絡的輸入特征,在使用Mels保留95%可解釋方差的PCA結果作為輸入特征時,取得了94.86%的F1值,相較其他時頻域特征具有明顯的優勢。
最終特征選擇的結果為在時域上使用4種包絡與譜熵的拼接,在時頻域上使用Mels保留95%可解釋方差的PCA結果。
2.3 消融試驗結果
多特征融合模塊由多尺度空洞卷積、協同融合與通道注意力機制串聯而成,為進一步驗證網絡中多特征融合的各子模塊在心音分割網絡中能發揮作用,針對這3個子模塊設計了消融試驗,試驗結果見表3。由于協同融合要求輸入的兩種特征在維度上保證一致,當不使用多尺度空洞卷積時,無法直接完成協同融合。當不使用協同融合時,將使用拼接的方式使兩個特征空間中的特征連接在一起。試驗結果表明,在不使用多特征融合時,心音分割模型能取得94.93%的F1值;在僅使用1種子模塊時,最高能取得95.38%的F1值;在同時使用2種子模塊時,最高能取得95.58%的F1值;試驗中使用的模型采用了3種子模塊,F1值能達到96.04%,F1值累計提升1.11%。與F1值類似,隨子模塊的增加,心音分割的精確率提升1.49%、靈敏度提升0.71%、錯誤率降低1.02%,均有一定改善。證明這3個模塊均能提升網絡心音分割性能,且具有一定的互補性。
2.4 分割性能評估
將本文的方法與現在幾種主流的心音分割方法進行對比,結果見表4,本文主要的對比方法有Messner等[16]使用的BiGRU網絡(state of the art,SOTA),Springer等[11]使用的LR-HSMM模型,Chen等[3]提出的Duration-LSTM網絡,Wang等[23]提出的TFAN網絡,以及常用于心音分割的BiLSTM網絡等。
本文網絡中分割模塊可使用BiGRU或BiLSTM,用兩種網絡獨立進行心音分割時,對比BiLSTM,BiGRU的F1值具有0.24%優勢,是本文網絡用到的分割模塊。此外,對比Springer團隊的模型,本文方法在測試集的全部樣本(Pre=95.65%,Se=95.42%,F1=96.04%,Err=3.92%),正常心音樣本(Pre=97.59%,Se=98.01%,F1=97.80%,Err=2.17%)及異常心音樣本(Pre=93.79%,Se=94.88%,F1=94.33%,Err=5.60%)上心音分割性能更出色。Messner等[16]通過試驗驗證在心音分割時,BiGRU能取得略勝于LR-HSMM的試驗結果,但在本試驗中,BiGRU模型的心音分割結果并不理想,可能因為該網絡主要在心音的開始與結尾片段預測出錯,端點現象明顯[33],導致網絡在10 s的心音長度上性能惡化。為改善端點現象,Wang等[23]在對測試集進行心音分割時,采用了重疊50%的切分,并對模型的輸出結果進行維特比譯碼,得到重疊部分最終分割結果。采用同樣思路,本文方法在測試集上的心音分割性能取得進一步提升(Pre=96.70%,Se=96.99%,F1=96.84%,Err=3.15%)。同時,試驗還向BiGRU輸入經過特征降維與特征選擇后的特征,在測試集的全部心音樣本上,此BiGRU模型取得的F1值相較SOTA模型有了7.58%的提升,但與本文方法相比時,本文方法具有1.11%的F1值優勢,證明特征降維、特征選擇與多特征融合過程均對該方法提升心音分割性能有幫助。
3 討論
在發展心音輔助診斷模型時,心音分割模型一般是其他任務模型的前置模型[34]。在實際的心音采集過程中,往往伴隨多種背景噪聲,基于信號特征的心音分割方法依賴于特征的判決門限選擇,對噪聲敏感。因此,傳統方法與深度學習網絡被更多地應用在心音分割領域,其中深度學習網絡中RNN網絡憑借出色的分割性能,受到了廣泛關注[16]。為實現高性能的心音分割,本文提出了一種基于多特征融合網絡的心音分割方法,并取得一定進步。
首先,現有的心音模型網絡模型對特征間的相關性很少討論,導致模型的輸入中包含了較多冗余信息,本文通過PCA克服了這一缺點。本文中特征降維試驗的結果表明PCA使輸入網絡的特征維度明顯減少,在特征選擇試驗中,對比不進行PCA處理,MFCCs在保留99%可解釋方差后進行PCA處理取得最佳的心音分割F1值提升了2.78%,而保留95%可解釋方差卻反而下降16.35%。可知在保留合適比例的可解釋方差時,特征維度減少,特征間相關性下降,能提升模型的性能,但過多舍棄可能導致心音有效信息丟失。
其次,本文通過多尺度空洞卷積、協同融合以及通道注意力機制對特征進行多特征融合處理,充分考慮特征間的差異性與相似性。心音的收縮期、舒張期的持續時間一般為208 ms、530 ms[33],在多尺度空洞卷積中,包含4種卷積感受野,使得網絡能適應不同個體的心率,同時這4種感受野與收縮期、舒張期以及整個心音周期時長匹配,能提取不同心音狀態下的深度特征。若在模型中不使用多尺度空洞卷積,為了使兩種特征空間中的特征維度一致,還可以用一個普通的卷積提取時頻域的深度特征,但該模型在心音分割任務上僅能實現95.22% 的F1值。對比發現,本文的模型在F1值上具有0.82%的優勢,證明多尺度空洞卷積在完成統一特征維度任務的同時,它的多種感受野也是多特征融合模塊使網絡性能提升的關鍵。在協同融合前,時域特征與多尺度空洞卷積提取的時頻域特征均在[0,1]內,“ ”關注了兩種維度的互補性,放大S1與S2的特征,使他們明顯區別于收縮期與舒張期,“
”關注了兩種維度的互補性,放大S1與S2的特征,使他們明顯區別于收縮期與舒張期,“ ”關注了兩種維度的共性[30],通過點乘使得較小的數值更趨近與0,拉開S1與S2的特征差異。此外,Hu等[31]證明通道注意力機制使用通道卷積,給不同特征通道賦予不同權重,使網絡在不同樣本上動態地調整對不同特征維度的關注度。多尺度空洞卷積、協同融合與通道注意力機制考慮了對不同患者心音的適應,同時充分利用時域、時頻域特征的共性、互補性,使兩個特征空間的特征實現更充分的多特征融合。
”關注了兩種維度的共性[30],通過點乘使得較小的數值更趨近與0,拉開S1與S2的特征差異。此外,Hu等[31]證明通道注意力機制使用通道卷積,給不同特征通道賦予不同權重,使網絡在不同樣本上動態地調整對不同特征維度的關注度。多尺度空洞卷積、協同融合與通道注意力機制考慮了對不同患者心音的適應,同時充分利用時域、時頻域特征的共性、互補性,使兩個特征空間的特征實現更充分的多特征融合。
最后,本文提出的方法能取得更好的心音分割性能并具有良好的泛化能力。在與其他方法的對比試驗中,本文的方法在精確率、靈敏度、F1值與錯誤率上,都取得了更好的結果,相比Messner等[16] 的方法,F1值提升9.49%,相較Springer等[11]的方法,F1值提升2.16%,試驗證明,本文的特征降維、特征選擇與多特征融合過程均有利于對本方法的心音分割性能提升。此外,PN-training-a完全不參與訓練,且數據分布也不同于其他數據集,異常心音占比更高。本文模型在PN-training-a整體樣本(Pre=96.28%,Se=96.53%,F1=96.41%,Err=3.59%)、正常樣本(Pre=97.38%,Se=97.51%,F1=97.44%,Err=2.56%)、異常樣本(Pre=95.81%,Se=96.11%,F1=95.96%,Err=4.03%)上均取得了較好的心音分割性能,證明本文模型具有良好的泛化能力。
但同時本研究所提方法也存在局限性。本文方法對異常心音樣本進行心音分割時,雖已取得較大的性能提升,但依舊具有上升空間。為此,在今后的試驗中,我們需要擴充數據集中異常心音樣本的數量,從而進一步提升網絡對這部分患者的心音分割性能。
利益沖突:無。
作者貢獻:潘帆負責組織研究,收集數據,修改論文;錢永軍負責設計、組織研究,修改論文;李莉參與設計、分析數據;趙啟軍、何培宇負責設計、組織研究;田翩參與設計、執行研究,撰寫論文;蔡杰負責收集、分析數據。
心血管疾病已成為全球最大的死亡原因,僅中國每年約有254萬人因心血管疾病死亡[1],盡早診斷對心血管疾病的治療極為關鍵。臨床醫學中常用的心血管疾病診斷方法包括電子計算機斷層掃描(computed tomography,CT)、心血管超聲、心臟聽診等,其中心臟聽診對設備要求較低,能避免診斷環節中使用昂貴的醫療設備給患者帶來的經濟負擔,常應用于心血管疾病的早期檢查。
在醫生進行臨床心臟聽診時關注的信號是心音,心音由心臟的機械震動傳導至體表產生,又被稱為心音圖(phonocardiogram,PCG)。一個基本心音會依次經歷4種狀態:第一心音(first heart sound,S1)、收縮期(systole,sys)、第二心音(second heart sound,S2)、舒張期(diastole,dis);見圖1。當心室開始收縮時,房室瓣關閉而產生S1,在收縮期,血液從心室經動脈瓣流向動脈,當心室開始舒張時,動脈瓣關閉而產生S2;在舒張期,血液從心房經房室瓣流向心室。心音分割的任務就是從心音圖中準確定位每一種狀態。
圖1
心音示意圖
臨床心音聽診的診斷結果需結合心音分割的結果分析,因此心音分割是心臟聽診中的一項重要任務。例如,在觀察患者是否出現心音分裂或強度異常時,需準確定位S1與S2,然后具體分析;在判斷患者是否出現異常心臟結構時,需準確定位舒張期與收縮期,當觀測到患者舒張期出現連續雜音,一般都是病理性雜音;而當患者出現收縮期雜音,則可能是病理性,也可能是正常心臟結構的血流量增加[2]。
近年來,在心音分割領域出現了許多有效的分割方法,現有的心音分割方法包括基于信號特征的心音分割、基于傳統模型的心音分割與基于深度學習網絡的心音分割[3]。
基于信號特征的心音分割[4–8]主要利用信號在時域、頻域、時頻域的信息。如曾勁云等[4]與Belmecheri等[5]利用心音的頻譜與包絡信息,Babu等[7]通過變分模態分解提取信號中的特征,Varghees等[8]通過經驗小波變換提取信號中的特征。這些方法在信號特征的基礎上,結合門限法實現心音分割,但判別門限對噪聲較為敏感,當背景噪聲較強時,會影響特征的包絡,而實踐中的心音往往伴隨著環境噪聲,背景噪聲是此方法在實踐中推廣的一個重大難題。
基于傳統模型的心音分割則是在信號特征的基礎上結合了其他傳統模型。例如隱馬爾可夫模型(hidden Markov model,HMM)[9-10]與隱半馬爾可夫模型(hidden semi-Markov model,HSMM)[11–15],這兩種模型從訓練集的觀察特征與狀態序列上學習狀態轉移概率、觀測概率、初始狀態概率等信息[13],實現在測試集上根據觀察特征預測對應的狀態序列,從而完成心音分割。HSMM相較HMM模型,還利用了狀態的持續時間概率分布作為模型的參數,能有效提升心音分割性能[11],但非規律性的心音與訓練集中樣本的狀態持續時間差異較大,模型的持續時間概率分布不再匹配,對這部分樣本,S1與S2分割出錯的可能性提升[16]。除此之外,Xu等[17]還利用聚類模型K-Means對基于信號特征的分割結果進行聚類,排除異常的識別結果,但這種方法對于雜音等級較高的異常心音,分割性能較差。
隨著深度學習網絡強大學習能力的展現,大量深度學習網絡也運用到了心音分割中,并取得了比上面兩種方法更好的性能表現。Renna等[18]與Chen等[19]均通過卷積神經網絡(convolutional neural networks,CNN)實現心音分割。但從理論上來講,CNN存在長時依賴問題,具體表現在容易丟失之前時刻提取的心音信息,相比之下,循環神經網絡(recurrent neural network,RNN)能取得更好的性能[20–22]。Messner等[16]對多種RNN的心音分割性能進行了比較,如長短時記憶網絡(long short term memory,LSTM)、門控循環單元(gated recurrent unit,GRU)及它們的雙向結構,試驗證明BiGRU能取得最佳的性能,且比HSMM模型表現更佳。此外,部分學者對LSTM模型進行了改進,如Chen等[3]提出Duration-LSTM,向網絡中加入患者心音的時長參數;Wang等[23]提出基于LSTM的TFAN網絡;Guo等[24]使用卷積與注意力機制,提出C-LSTM-A網絡,都相較LSTM取得了一定的心音分割性能提升。
基于深度學習網絡的心音分割已取得較好的結果,之前研究往往聚焦于分割網絡結構,但實際上特征工程是網絡模型中的重要一環,對網絡的性能有重要影響。前面的網絡模型輸入特征較為單一,或者特征間的融合處理較為簡單,未充分利用不同特征間的區別與聯系,本研究在BiGRU網絡的基礎上,重點關注網絡輸入特征的處理,實現了一個基于多特征融合網絡的心音分割方法。
1 資料與方法
1.1 數據采集
試驗中使用的數據集來自2016 CinC/PhysioNet心音挑戰賽[25]。該比賽的訓練集為開源數據集,常用于心音分割方法的性能評估,由6個獨立的機構提供,記為PN-training-a至PN-training-f,包括從764例患者中采集的3 153段正常或異常心音記錄,長度5~120 s,采樣率為2 000 Hz。數據集包含正常心音與異常心音,其中異常心音記錄樣本主要與二尖瓣脫垂(mitral valve prolapse,MVP)、良性雜音(benign)、主動脈疾病(aortic disease,AD)、其他病理狀況(miscellaneous pathological conditions,MPC)、冠狀動脈疾病(coronary artery disease,CAD)、二尖瓣反流(mitral regurgitation,MR)、主動脈狹窄(aortic stenosis,AS)和病理學(pathologic)相關。
此外,這個數據集中還標注了每段心音4種狀態的開始與結束時刻,以及信號質量差的心音片段。在本試驗中,剔除了含質量差片段的313段心音,并按將同一例患者的數據僅包含在一個數據集中的規則,將剩余數據劃分為訓練集與測試集,最終得到的數據集見表1。
1.2 整體框架
本文提出的方法包括數據集劃分、預處理、特征提取、特征降維、特征選擇與網絡訓練等步驟,主要處理過程的框架見圖2。
圖2
心音分割方法整體框架
PCA:主成分分析
1.3 特征提取
心音的主要能量分布在150 Hz以下,對數據集的音頻,進行了如下處理:首先通過一個截止頻率為25 Hz與400 Hz、階數為4的巴特沃斯帶通濾波器濾除心音中的高頻噪聲與低頻直流偏置,并將音頻不重疊地切分為10 s的音頻,<2 s的音頻可能不含完整的心音,這部分音頻在試驗中舍棄,其他<10 s的音頻末端補0。切分后,訓練集與測試集分別包含5 396、1 985段音頻。
對心音進行特征提取時,分別從時頻域與時域兩種特征空間提取特征,兩個特征空間中主要包含如下特征。
(1)時頻域特征:① 梅爾譜圖(Mel spectrum,Mels):頻譜圖能表現音頻的短時頻譜隨時間的變化,Mels在頻譜圖的基礎上,進一步使用梅爾濾波器組來設計頻帶,更符合人的聽覺機理,試驗中使用了包含64個濾波器的梅爾濾波器組計算Mels,濾波器頻率范圍為25~400 Hz;② 梅爾倒譜系數(mel-frequency cepstral coefficients,MFCCs):MFCCs常用于語音識別中,試驗中使用含20個濾波器的梅爾濾波器組提取了20個MFCCs,濾波器的頻率范圍為25~400 Hz,并以9為窗長提取了MFCCs的20個一階導、20個二階導。
(2)時域特征:① 包絡特征(envelopes):包絡特征是心音分割中用到最多的特征,包含同態包絡、希爾伯特包絡、小波包絡與功率譜密度[11];② 譜熵(spectral entropy,SE):譜熵常用于音頻的端點檢測中,計算信號歸一化譜概率密度函數的熵,表現信號在頻域分布的無序性隨時間的變化[26]。
其中,Mels、MFCCs與譜熵的計算均需進行分幀操作,試驗中使用80 ms窗長、20 ms幀移的漢明窗完成;計算包絡特征時為保證與其他特征具有同樣的特征采樣率,進行了采樣率為50 Hz的降采樣;此外,對于每段音頻的不同特征,在特征提取后還進行了歸一化處理。
為獲取每段心音真實的分割結果,試驗根據給出的狀態起止時刻標注,每20 ms進行一次狀態標記,最終得到采樣率為50 Hz的真實狀態序列。
1.4 特征降維
完成特征提取后,所得到的特征存在維度過高與維度間相關性較強的問題。例如,Mels一般維度較高,相鄰頻段的帶寬部分重疊,頻段內計算的能量相關性較強[27]。試驗通過主成分分析(principal components analysis,PCA)來實現特征降維[28],同時減少輸入特征間的相關性。
PCA主要運用了相關矩陣與特征值分解,將初始特征向量轉換為一組不相關的特征向量。對于含k個樣本的n維特征向量,通過式(1)對每個維度中心化,得到中心化特征向量;按式(2)求中心化特征向量的協方差矩陣,式中{·}表示數學期望;對進行特征值分解得到一組從大到小排序的特征值與對應的特征向量;若希望保留個主成分,則按式(3)得到維的降維特征,其中第個主成分的可解釋方差為,貢獻度為。
| '/> |
| '/> |
|
1.5 網絡模型
本文提出的網絡結構見圖3,經過特征選擇后,從兩個特征空間中選擇的心音分割性能最佳的特征作為網絡的輸入。網絡先完成多特征融合任務,得到融合特征,再將融合特征送入分割模塊,完成心音分割任務,得到預測的狀態序列。該網絡在多特征融合模塊主要使用了多尺度空洞卷積、協同融合與通道注意力機制(attention),在分割模塊使用了BiGRU網絡。
圖3
網絡結構圖
1.5.1 多尺度空洞卷積
在特征選擇后,得到時域特征與時頻域特征,試驗中與一般不相等,如本試驗中=5,=6。為確保協同融合前兩個特征空間中特征維度一致,網絡中使用了多尺度空洞卷積改變時頻域特征維度[29]。
該網絡的多尺度空洞卷積使用了膨脹系數分別為1、2、3、4的4種卷積核對進行空洞卷積,得到4種尺度的特征圖,每個卷積核的大小為10,對應的感受野大小分別為200 ms、380 ms、560 ms、740 ms。將4種特征圖拼接得到拼接特征,通過卷積與激活等操作逐步降維,得到與時域特征維度一致的時頻域特征。使用包含個神經元的卷積層對進行處理時,兩個特征空間中的特征維度也能實現統一,但相比而言,多尺度空洞卷積聚合了多尺度的心音特征,能提取更豐富的心音上下文信息。
1.5.2 協同融合
將時域特征與多尺度空洞卷積處理后的時頻域特征送入協同融合模塊(圖3),其過程描述為:
|
式中“”表示點加,“”表示點乘,按式(4)進行計算,得到協同融合的輸出特征,與輸入特征具有相同的維度。Fu等[30]的研究證明,雖然不同特征通過拼接的方式也能實現融合,但這樣的融合方式往往會使模型的訓練結果陷入局部最優,如在本試驗中偏向從時域特征學習心音分割。
1.5.3 通道注意力機制
為根據不同樣本動態調整不同特征通道的重要性權重,網絡在協同融合的輸出特征上使用了通道注意力機制[31]。通道注意力機制可描述為:
|
|
其中(·)表示全局平均池化,(·)表示第個全連接層。對協同融合后的得到的特征,根據式(5)計算出的每個通道的注意力權重,通過式(6)完成加權后,得到融合特征。
1.5.4 雙向門控循環單元
門控循環單元由Chung 等[32]提出,通過重置門使網絡遺忘過去時刻的狀態,通過更新門決定網絡的更新狀態,GRU網絡由多個門控循環單元構成。
假設網絡的前一時的刻激活狀態為,當前的輸入為,那么網絡重置門、候選狀態與更新門分別表示為式(7)~(9)。其中重置門主要用在候選狀態的計算中,決定對的遺忘程度,當接近0時,可認為當前單元的候選狀態僅由當前輸入決定;更新門主要用在當前時刻的激活狀態的計算中,用來決定對與的激活程度。最終由式(10)得到,可理解為候選狀態與的線性組合。
|
|
|
|
上面的GRU單元的當前狀態與前一時刻的激活狀態有關,而在實際的心音分割過程中,某一時刻的狀態判斷需綜合參考前一時刻激活狀態與后一時刻激活狀態,故試驗中使用的是BiGRU。在BiGRU中,兩個單獨的GRU隱藏層分別處理兩個方向上的數據,前向激活狀態描述為式(11),反向激活狀態描述為式(12),則BiGRU的激活狀態為與的組合。
|
|
1.6 評估指標
對方法分割結果進行評估時,試驗比較了真實狀態序列與預測結果中的每種狀態,當某狀態的起止時間與標簽均一致時,則認為該狀態判斷正確,同時,本文允許每種狀態的起止點存在40 ms的誤差。對于每種狀態,記錄了下列事件的發生次數:真陽性(true positive,TP):真實狀態序列與預測結果中,狀態標簽一致,起止時間在誤差允許范圍內;真實發生(number of ground truth,GTN):在真實狀態序列中,該狀態出現;預測發生(number of prediction,PN):在預測結果中,該狀態出現。
由上面的數據,根據公式(13)~(18)計算精確率(precision,Pre)、靈敏度(sensitivity,Se)、F1值與錯誤率(error rate,Err),作為心音分割性能評估指標。
|
|
|
|
|
|
1.7 實現細節
在通過PCA完成特征降維時,相比時域特征,時頻域特征維度較高,主要在時頻域上進行特征降維。在對PCA保留維數的選擇上,分別選擇保留99%可解釋方差與保留95%可解釋方差的對應維數;在計算式(2)中協方差矩陣時,使用訓練集中樣本進行估計,并將得到的特征向量通過式(3)分別應用在訓練集與測試集上,完成特征降維。
本文網絡基于pytorch1.11框架實現,輸出狀態序列包含5種狀態,分別是補0、S1、收縮期、S2與舒張期;網絡中所有的卷積均采用“same”卷積模式,保證卷積前后特征的幀數不變;網絡的BiGRU參數參考Messner等[16]得到的最優參數:“dropout”設置為0.1,雙層,每個隱藏狀態包含100個特征;在訓練網絡參數的過程中使用了ADAM優化器與交叉熵損失函數。此外,為均衡模型在正常與異常心音上的分割性能,在訓練模型時,對正常心音樣本與異常心音樣本采用了不同的采樣權重,使得兩者等比例參與訓練。
在模型比較時,為了綜合考慮每種心音狀態,每次試驗對S1、收縮期、S2、舒張期的評估結果取均值。在網絡訓練的過程中,試驗結果具有隨機性,為了提高結果評估結果的可靠性,在每種方法上進行了10次訓練,每次訓練均完成200輪迭代,最終對10次訓練的結果取均值與方差。在對其他模型進行復現時,采用了與本文一致的數據集劃分。但由于Springer等[11]與Wang等[23]使用的模型在預測時候使用了維特比譯碼,且在分割狀態中僅存在心音的4種狀態,在復現時使用了參考論文中的切分方法,未對心音進行補0。其他對比模型采用了與本文相同的心音切分方法。
2 結果
2.1 特征降維結果
在訓練集上,根據式(2)分別估算心音Mels與MFCCs的協方差矩陣,對兩者實現特征降維。本文提取的Mels特征維度為64維,MFCCs特征維度為60維,在保留99%可解釋方差后,Mels的特征降至11維,MFCCs的特征維度降至7維;在保留95%可解釋方差后,Mels的特征維度降至6維,MFCCs的特征維度降至4維。降維后的特征不同維度間線性無關,且保留了原始特征的主要信息。
2.2 特征選擇結果
在BiGRU網絡上分別利用兩種特征空間的特征進行心音分割任務,從兩種特征維度中分別選取表現最佳的特征,結果見表2。
在時域上,由于譜熵為一維特征,維度較低,未進行基于譜熵的心音分割試驗。試驗結果表明,相比僅使用4種包絡作為輸入特征,4種包絡與譜熵的拼接在準確率、靈敏度、F1值與錯誤率的表現上都有一定提升。在時頻域上,MFCCs與Mels均包含心音豐富的時頻域信息,經PCA處理后保留了時頻域信息中的大部分可解釋方差,試驗中分別使用MFCCs、Mels與它們PCA處理后的特征作為網絡的輸入特征,在使用Mels保留95%可解釋方差的PCA結果作為輸入特征時,取得了94.86%的F1值,相較其他時頻域特征具有明顯的優勢。
最終特征選擇的結果為在時域上使用4種包絡與譜熵的拼接,在時頻域上使用Mels保留95%可解釋方差的PCA結果。
2.3 消融試驗結果
多特征融合模塊由多尺度空洞卷積、協同融合與通道注意力機制串聯而成,為進一步驗證網絡中多特征融合的各子模塊在心音分割網絡中能發揮作用,針對這3個子模塊設計了消融試驗,試驗結果見表3。由于協同融合要求輸入的兩種特征在維度上保證一致,當不使用多尺度空洞卷積時,無法直接完成協同融合。當不使用協同融合時,將使用拼接的方式使兩個特征空間中的特征連接在一起。試驗結果表明,在不使用多特征融合時,心音分割模型能取得94.93%的F1值;在僅使用1種子模塊時,最高能取得95.38%的F1值;在同時使用2種子模塊時,最高能取得95.58%的F1值;試驗中使用的模型采用了3種子模塊,F1值能達到96.04%,F1值累計提升1.11%。與F1值類似,隨子模塊的增加,心音分割的精確率提升1.49%、靈敏度提升0.71%、錯誤率降低1.02%,均有一定改善。證明這3個模塊均能提升網絡心音分割性能,且具有一定的互補性。
2.4 分割性能評估
將本文的方法與現在幾種主流的心音分割方法進行對比,結果見表4,本文主要的對比方法有Messner等[16]使用的BiGRU網絡(state of the art,SOTA),Springer等[11]使用的LR-HSMM模型,Chen等[3]提出的Duration-LSTM網絡,Wang等[23]提出的TFAN網絡,以及常用于心音分割的BiLSTM網絡等。
本文網絡中分割模塊可使用BiGRU或BiLSTM,用兩種網絡獨立進行心音分割時,對比BiLSTM,BiGRU的F1值具有0.24%優勢,是本文網絡用到的分割模塊。此外,對比Springer團隊的模型,本文方法在測試集的全部樣本(Pre=95.65%,Se=95.42%,F1=96.04%,Err=3.92%),正常心音樣本(Pre=97.59%,Se=98.01%,F1=97.80%,Err=2.17%)及異常心音樣本(Pre=93.79%,Se=94.88%,F1=94.33%,Err=5.60%)上心音分割性能更出色。Messner等[16]通過試驗驗證在心音分割時,BiGRU能取得略勝于LR-HSMM的試驗結果,但在本試驗中,BiGRU模型的心音分割結果并不理想,可能因為該網絡主要在心音的開始與結尾片段預測出錯,端點現象明顯[33],導致網絡在10 s的心音長度上性能惡化。為改善端點現象,Wang等[23]在對測試集進行心音分割時,采用了重疊50%的切分,并對模型的輸出結果進行維特比譯碼,得到重疊部分最終分割結果。采用同樣思路,本文方法在測試集上的心音分割性能取得進一步提升(Pre=96.70%,Se=96.99%,F1=96.84%,Err=3.15%)。同時,試驗還向BiGRU輸入經過特征降維與特征選擇后的特征,在測試集的全部心音樣本上,此BiGRU模型取得的F1值相較SOTA模型有了7.58%的提升,但與本文方法相比時,本文方法具有1.11%的F1值優勢,證明特征降維、特征選擇與多特征融合過程均對該方法提升心音分割性能有幫助。
3 討論
在發展心音輔助診斷模型時,心音分割模型一般是其他任務模型的前置模型[34]。在實際的心音采集過程中,往往伴隨多種背景噪聲,基于信號特征的心音分割方法依賴于特征的判決門限選擇,對噪聲敏感。因此,傳統方法與深度學習網絡被更多地應用在心音分割領域,其中深度學習網絡中RNN網絡憑借出色的分割性能,受到了廣泛關注[16]。為實現高性能的心音分割,本文提出了一種基于多特征融合網絡的心音分割方法,并取得一定進步。
首先,現有的心音模型網絡模型對特征間的相關性很少討論,導致模型的輸入中包含了較多冗余信息,本文通過PCA克服了這一缺點。本文中特征降維試驗的結果表明PCA使輸入網絡的特征維度明顯減少,在特征選擇試驗中,對比不進行PCA處理,MFCCs在保留99%可解釋方差后進行PCA處理取得最佳的心音分割F1值提升了2.78%,而保留95%可解釋方差卻反而下降16.35%。可知在保留合適比例的可解釋方差時,特征維度減少,特征間相關性下降,能提升模型的性能,但過多舍棄可能導致心音有效信息丟失。
其次,本文通過多尺度空洞卷積、協同融合以及通道注意力機制對特征進行多特征融合處理,充分考慮特征間的差異性與相似性。心音的收縮期、舒張期的持續時間一般為208 ms、530 ms[33],在多尺度空洞卷積中,包含4種卷積感受野,使得網絡能適應不同個體的心率,同時這4種感受野與收縮期、舒張期以及整個心音周期時長匹配,能提取不同心音狀態下的深度特征。若在模型中不使用多尺度空洞卷積,為了使兩種特征空間中的特征維度一致,還可以用一個普通的卷積提取時頻域的深度特征,但該模型在心音分割任務上僅能實現95.22% 的F1值。對比發現,本文的模型在F1值上具有0.82%的優勢,證明多尺度空洞卷積在完成統一特征維度任務的同時,它的多種感受野也是多特征融合模塊使網絡性能提升的關鍵。在協同融合前,時域特征與多尺度空洞卷積提取的時頻域特征均在[0,1]內,“”關注了兩種維度的互補性,放大S1與S2的特征,使他們明顯區別于收縮期與舒張期,“”關注了兩種維度的共性[30],通過點乘使得較小的數值更趨近與0,拉開S1與S2的特征差異。此外,Hu等[31]證明通道注意力機制使用通道卷積,給不同特征通道賦予不同權重,使網絡在不同樣本上動態地調整對不同特征維度的關注度。多尺度空洞卷積、協同融合與通道注意力機制考慮了對不同患者心音的適應,同時充分利用時域、時頻域特征的共性、互補性,使兩個特征空間的特征實現更充分的多特征融合。
最后,本文提出的方法能取得更好的心音分割性能并具有良好的泛化能力。在與其他方法的對比試驗中,本文的方法在精確率、靈敏度、F1值與錯誤率上,都取得了更好的結果,相比Messner等[16] 的方法,F1值提升9.49%,相較Springer等[11]的方法,F1值提升2.16%,試驗證明,本文的特征降維、特征選擇與多特征融合過程均有利于對本方法的心音分割性能提升。此外,PN-training-a完全不參與訓練,且數據分布也不同于其他數據集,異常心音占比更高。本文模型在PN-training-a整體樣本(Pre=96.28%,Se=96.53%,F1=96.41%,Err=3.59%)、正常樣本(Pre=97.38%,Se=97.51%,F1=97.44%,Err=2.56%)、異常樣本(Pre=95.81%,Se=96.11%,F1=95.96%,Err=4.03%)上均取得了較好的心音分割性能,證明本文模型具有良好的泛化能力。
但同時本研究所提方法也存在局限性。本文方法對異常心音樣本進行心音分割時,雖已取得較大的性能提升,但依舊具有上升空間。為此,在今后的試驗中,我們需要擴充數據集中異常心音樣本的數量,從而進一步提升網絡對這部分患者的心音分割性能。
利益沖突:無。
作者貢獻:潘帆負責組織研究,收集數據,修改論文;錢永軍負責設計、組織研究,修改論文;李莉參與設計、分析數據;趙啟軍、何培宇負責設計、組織研究;田翩參與設計、執行研究,撰寫論文;蔡杰負責收集、分析數據。